In 2025, mobile apps aren’t just smarter they’re self-sufficient. Thanks to breakthroughs in edge computing and lightweight language models, apps are increasingly running AI models locally on devices, without depending on cloud APIs or external servers.
This shift is called Edge-First AI — a new paradigm where devices process AI workloads at the edge, delivering fast, private, and offline experiences to users across India, the US, and beyond.
🌐 What Is Edge-First AI?
Edge-First AI is the practice of deploying artificial intelligence models directly on devices — mobile phones, IoT chips, microcontrollers, wearables, or edge servers — rather than relying on centralized data centers or cloud APIs.
This allows for:
- ⚡ Instant response times (no network latency)
- 🔒 Better privacy (data stays on-device)
- 📶 Offline functionality (critical in poor network zones)
- 💰 Cost reduction (no server or token expenses)
📱 Examples of Offline AI in Mobile Apps
- Note-taking apps: On-device summarization of text, using Gemini Nano or LLaMA
- Camera tools: Real-time image captioning or background blur with CoreML
- Fitness apps: Action recognition from sensor data using TensorFlow Lite
- Finance apps: OCR + classification of invoices without network access
- Games: On-device NPC behavior trees or dialogue generation from small LLMs
🧠 Common Models Used in Edge Inference
- Gemini Nano – Android on-device language model for summarization, response generation
- LLaMA 3 8B Quantized – Local chatbots, cognitive actions (q4_K_M or GGUF)
- Phi-2 / Mistral 7B – Compact LLMs for multitask offline AI
- MediaPipe / CoreML Models – Vision & pose detection on-device
- ONNX-Tiny + TensorFlow Lite – Accelerated performance for CPU + NPU
💡 Why This Matters in India & the US
India:
- Many users live in areas with intermittent connectivity (tier-2/tier-3 cities)
- Cost-conscious devs prefer tokenless, cloudless models for affordability
- AI tools for education, productivity, and banking need to work offline
US:
- Enterprise users demand privacy-first LLM solutions (HIPAA, CCPA compliance)
- Edge inference is being used in AR/VR, wearables, and health tech
- Gamers want low-latency AI without ping spikes
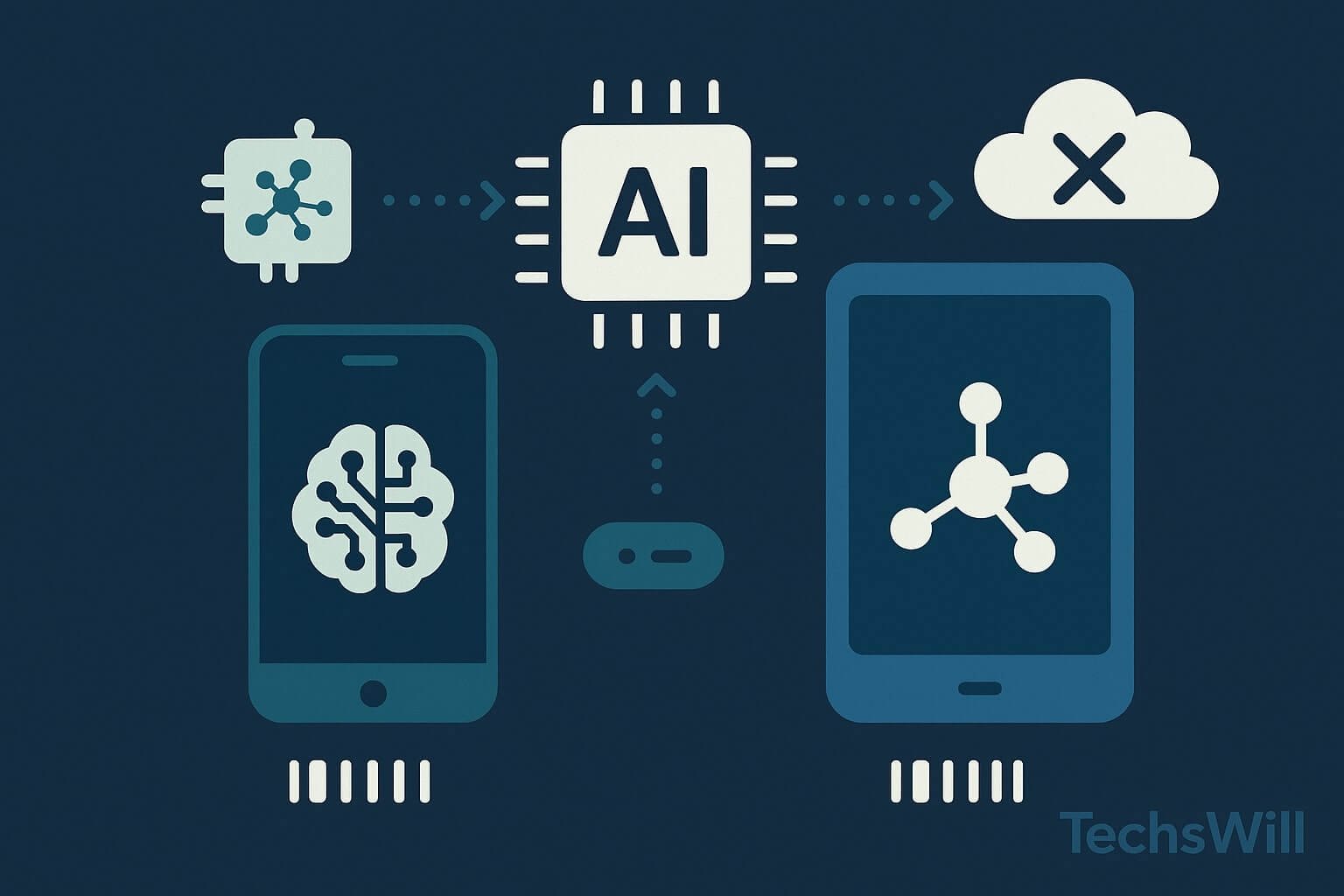
⚙️ Technical Architecture of Edge-First AI
Edge inference requires a rethinking of mobile architecture. Here’s what a typical stack looks like:
- Model Storage: GGUF, CoreML, ONNX, or TFLite format
- Runtime Layer: llama.cpp (C++), ONNX Runtime, Apple’s CoreML Runtime
- Acceleration: iOS Neural Engine (ANE), Android NPU, GPU offloading, XNNPack
- Memory: Token window size + output buffers must be optimized for mobile RAM (2–6GB)
Typical Flow:
User Input → Context Assembler → Quantized Model → Token Generator → Output Parser → UI
🔧 SDKs & Libraries You Need to Know
- Google AICore SDK (Android) — Connects Gemini Nano to on-device prompt sessions
- Apple Intelligence APIs (iOS) — AIEditTask and LiveContext integration
- llama.cpp / llama-rs — C++/Rust inference engines with mobile ports
- ggml / gguf — Efficient quantized formats for portable models
- ONNX Mobile + ORT — Open standard for cross-platform edge AI
- Transformers.js / Metal.js — LLM inference in the browser or hybrid app
🧪 Testing Offline AI Features
- 🔁 Compare cloud vs edge outputs with test fixtures
- 📏 Measure latency using A/B device types (Pixel 8 vs Redmi 12)
- 📶 Test airplane mode / flaky network conditions with simulated toggling
- 🔍 Validate token trimming + quantization does not degrade accuracy
📉 Cost and Performance Benchmarks
| Model | RAM | Latency (1K tokens) | Platform |
|---|---|---|---|
| Gemini Nano | 1.9 GB | 180ms | Android (Pixel 8) |
| LLaMA 3 8B Q4_K_M | 5.2 GB | 420ms | iOS M1 |
| Mistral 7B Int4 | 4.7 GB | 380ms | Desktop GPU |
| Phi-2 | 2.1 GB | 150ms | Mobile / ONNX |
💡 When Should You Choose Edge Over Cloud?
- 💬 If you want conversational agents that work without internet
- 🏥 If your app handles sensitive user data (e.g. medical, education, finance)
- 🌏 If your user base lives in low-connectivity regions
- 🎮 If you’re building real-time apps (gaming, media, AR, camera)
- 📉 If you want to avoid costly OpenAI / Google API billing
🔐 Privacy, Compliance & Ethical Benefits
Edge inference isn’t just fast — it aligns with the evolving demands of global users and regulators:
- Data Sovereignty: No outbound calls = no cross-border privacy issues
- GDPR / CPRA / India DPDP Act: Local model execution supports compliance
- Audit Trails: On-device AI enables logged, reversible sessions without cloud storage
⚠️ Note: You must still disclose AI usage and model behavior inside app permission flows and privacy statements.
💼 Developer Responsibilities in Edge AI Era
To ship safe and stable edge AI experiences, developers need to adapt:
- 🎛 Optimize models using quantization (e.g. GGUF, INT4) to fit memory budgets
- 🧪 Validate outputs on multiple device specs
- 📦 Bundle models responsibly using dynamic delivery or app config toggles
- 🔒 Offer AI controls (on/off, fallback mode, audit) to users
- 🔁 Monitor usage and quality with Langfuse, TelemetryDeck, or PromptLayer (on-device mode)
🌟 Real-World Use Cases (India + US)
🇮🇳 India
- Language Learning: Apps use tiny LLMs to offer spoken response correction offline
- Healthcare: Early-stage symptom classifiers in remote regions
- e-KYC: Offline ID verification + face match tools with no server roundtrip
🇺🇸 United States
- Wearables: Health & fitness devices running AI models locally for privacy
- AR/VR: Generating prompts, responses, UI feedback entirely on-device
- Military / Defense: Air-gapped devices with local-only AI layers for security
🚀 What’s Next for Edge AI in Mobile?
- LLMs with < 1B params will dominate smart assistants on budget devices
- All premium phones will include AI co-processors (Apple ANE, Google TPU, Snapdragon AI Engine)
- Edge + Hybrid models (Gemini local fallback → Gemini Pro API) will become the new default
- Developers will use “Intent Graphs” to drive fallback logic across agents